Duplicate feature requests aren’t “noise.” They are a data integrity bug in your product pipeline. They split votes, fork context, and create parallel issues that drift until someone ships the wrong thing with the right confidence. Linear stays fast because it assumes you stay disciplined. The second you treat it like a public inbox, it turns into the same bloated enterprise graveyard you swore you’d never rebuild.
This playbook prevents feature request duplicates in Linear without manual dedup work. Chapter 1 sets the operating rules for PMs and engineering leads. It defines one intake path and one canonical issue. Chapter 2 hardens your Linear model with required fields, templates, and consistent “problem-first” titling. Chapter 3 wires automation. It uses search, similarity matching, and webhooks to auto-link, auto-close, or auto-merge duplicates. Chapter 4 shows how to run the workflow in production with audits, metrics, and failure modes you can actually debug.
One Door Into Linear: The Only Reliable Way to Stop Feature Request Duplicates
Duplicates happen when intake is a choose-your-own-adventure. A PM hears it in Slack, support logs it in a spreadsheet, and sales emails an engineer. Then Linear gets three issues for the same thing.
Preventing feature request duplicates in Linear starts with a single, standardized intake path. One entry point forces every idea, bug, and initiative through the same funnel before it hits team backlogs. When requests arrive through multiple channels, visibility collapses. Teams can’t see what already exists, so they rebuild it.
A good intake path is boring by design. Use one form or portal that captures consistent fields like objective, impact, and urgency. Make it easier than the old path, or people will route around it. From there, triage can be manual or automated, but it must happen before work is assigned. This is where similar requests get grouped, duplicates get flagged, and ambiguous asks get pushed back for clarification. Next, route items from a common backlog into team-specific backlogs. That hierarchy prevents two teams from pulling the same work in parallel.
The workflow needs rules, not heroics. Define validation and approval steps based on type, value, risk, or business unit. Check feasibility, budget, and duplication up front. Automate routing where possible, and track the pipeline with dashboards so PMs and engineering leads can see volume, bottlenecks, and recurring duplicates. Ownership should be explicit: PMs own prioritization, engineering leads own capacity matching. Then measure cycle time, first-time approval rate, duplicate frequency, and satisfaction to adjust.
Resistance is normal. Use quick guides, champions, and a pilot. Allow exceptions, but log them.
How Feedvote solves this Feedvote gives you a single intake path that consolidates requests before they fragment into duplicate Linear issues. It centralizes incoming feedback and supports structured capture, so triage starts with consistent data. It also fits teams that collect feedback across channels, without letting those channels become separate backlogs. When you’re ready, you can connect the intake path directly to Linear using sync customer requests to Linear, so Linear stays the execution system, not the dumping ground.
Make Linear Dedupe Work: Standardize Titles, Fields, and IDs So “Same Request” Looks the Same

Duplicates in Linear don’t happen because your team is careless. They happen because the “same” feature request arrives with different words, missing fields, and no stable identifier.
If you want deduplication without manual cleanups, you first need records that are comparable. Standardization is that groundwork. When “Acme Services” and “Acme Svc” collapse into one agreed format, matching gets easier. Consistent formatting also helps fuzzy, phonetic, and cross-field matching stop missing obvious repeats. The research is clear: consistency improves both precision (fewer false positives) and recall (fewer misses), with benchmarks showing 96% match rates when the data layer is clean.
For Linear feature requests, the equivalent is a strict submission contract. Define naming rules and required fields that make a request uniquely identifiable. Require the same minimum payload every time (request title pattern, customer/org, source, and any key contact field you use). Keep the “master” set clean by merging redundant items and archiving dormants so future matching has better reference data.
Unique identifiers matter just as much. Across systems, you need one stable primary key per request event. Use an idempotency key or transaction/request ID so repeated submissions become detectable repeats, not new issues. If you can’t get a natural ID, generate one consistently (timestamps or hashes are common patterns in the research). Consolidate sources when possible and audit them, because hidden overlap across sources is common and can be 25–30%.
How Feedvote solves this Feedvote standardizes feedback at capture time, before it lands in Linear. You can require the fields you need and keep formatting consistent, so duplicates don’t hide behind wording. Feedvote keeps a clean system-of-record for requests, which makes matching and merging safer. If you’re syncing requests into Linear, this workflow reduces the dedup burden before you add automation like similarity search and webhooks.
Internal workflow reference: sync customer requests to Linear.
Automated Dedup in Linear: Webhook → Search → Similarity → Close the Copy
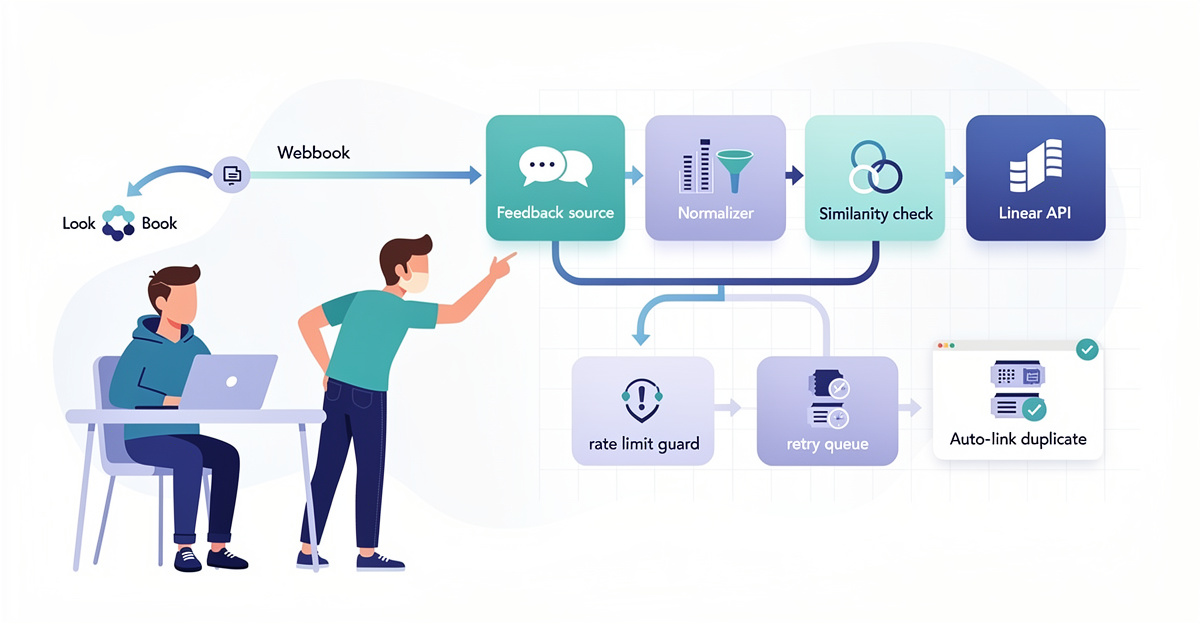
Duplicates show up the moment a new Linear issue lands. If you only catch them in triage, you’ve already paid the context-switch cost.
Linear doesn’t natively automate dedup with similarity detection plus webhooks. So the workflow is: trigger on creation, pull context, find candidates, score similarity, then take an action.
Start with a Linear webhook subscription for Issue Created. Linear will POST the issue payload to your endpoint with fields like title, description, labels, and team ID. Use ngrok for quick endpoint testing, then move to a stable hosted or self-hosted receiver. On receipt, extract the minimal fields you’ll match on (usually title + description), and resolve team or cycle metadata through Linear’s API if you need it.
Next, run a two-step candidate pipeline. First, call Linear’s GraphQL search (searchIssues) to fetch likely matches within the same team and relevant states. Keep it narrow to avoid pulling huge context. Then compute similarity outside Linear using an embeddings service (for example OpenAI embeddings or Sentence Transformers) against the candidate set. Use a clear thresholding policy: auto-dedup at high confidence (e.g., cosine similarity > 0.85), and route borderline matches (e.g., 0.7–0.85) to a human.
For actions, use Linear API mutations to comment “Duplicate of …” and close the new issue (many teams map this to a “Canceled” state). If unique, continue downstream steps like Slack notifications.
How Feedvote solves this Feedvote reduces the duplicate flood before it hits Linear by centralizing intake and normalization. Then it can sync validated requests into Linear in a controlled way, so you create fewer near-copies in the first place. You still keep Linear as the system of record, but Feedvote becomes the gate that enforces consistency. If you’re already wiring automations, start from this workflow: sync customer requests to Linear.
Competitors like bespoke scripts can match this pipeline, but you own every edge case and token scope. Feedvote is the better workflow when you want fewer duplicates created upstream and less custom glue to maintain.
Keep Duplicate Prevention Working in Linear: Audits, Flow Metrics, and Known Failure Modes

Your dedup setup in Linear will drift. The first sign is a backlog full of “same ask, different phrasing” issues that nobody trusts.
If you want to prevent feature request duplicates in Linear without manual dedup work, the workflow has to stay stable under real usage. That means explicit audits, a small set of flow metrics, and named failure modes that you monitor like any other production system.
Start by mapping stages with zero ambiguity. Linear works best with a sequential flow (Backlog → In Progress → Review → Done). Add statuses that expose waiting states, like “Waiting on Stakeholder,” so duplicate requests don’t hide behind “In Progress.” Document entry and exit criteria per status in Linear docs. “In Progress” must mean active work, not “someone glanced at it.” Keep WIP limits conservative, even if you use a simple three-column board. When WIP blows up, duplicates multiply because people stop searching and start filing.
Run an implementation audit on a cadence. Weekly flow reviews catch non-compliance early. Use retrospectives to adjust policies and roles, and keep procedures standardized so ownership is obvious. Track cycle time and throughput in Linear Insights, then watch for stalls and blocker frequency. If cycle time spikes in QA or Review, duplicates will accumulate upstream. Treat WIP violations and escalation frequency as signals that your dedup automation is being bypassed.
Common failure modes are predictable: bottlenecks, ambiguity, overload, and missing feedback loops. Mitigate them with explicit statuses, WIP limits, and escalation rules (overdue → notify). Test the workflow end-to-end after changes, and keep issue histories coherent with threads.
How Feedvote solves this Feedvote reduces duplicate creation pressure by centralizing incoming feedback before it hits Linear. You get a cleaner handoff into your Linear workflow, which makes audits and flow metrics mean something. When your intake is structured, your Linear statuses and WIP limits stay enforceable. For the mechanics of keeping intake and Linear aligned, see this guide on syncing customer requests to Linear.
Final thoughts
Manual dedup is expensive because it scales with attention, not traffic. If feature requests are coming from real users, the volume will grow. Linear will not save you from duplicate chaos. It will only reflect it faster.
Preventing feature request duplicates in Linear without manual dedup work is a systems problem. You solve it with one intake path, one canonical issue, and enforced structure that makes matching deterministic. You then automate the boring parts. Use similarity checks before issue creation. Use webhooks to auto-link and auto-close. Protect the Linear API with rate-limit guards and retry queues. Track false merges like you track incidents. A 1% false merge rate is still a weekly fire at scale.
Keep Linear as the execution system, not the dumping ground. If you want speed, treat duplicates as a bug. Then ship the fix.
Start using Feedvote to deduplicate and auto-merge feature requests into Linear—eliminate manual triage waste today.
Learn more: https://feedvote.app
About us
Feedvote is a customer feedback + public roadmap platform. It replaces Canny and Productboard for teams who want less bloat, lower cost, and faster workflows. It integrates deeply with Linear, but works as your source of truth for feedback.
It centralizes intake so you do not triage the same request from five channels. It supports dedup and merge behavior so Linear receives one canonical issue with linked evidence. It keeps vote counts and customer context attached to the right work item. It avoids the slow slide into a bloated enterprise graveyard where every request becomes a ticket, every ticket becomes a meeting, and nothing ships.