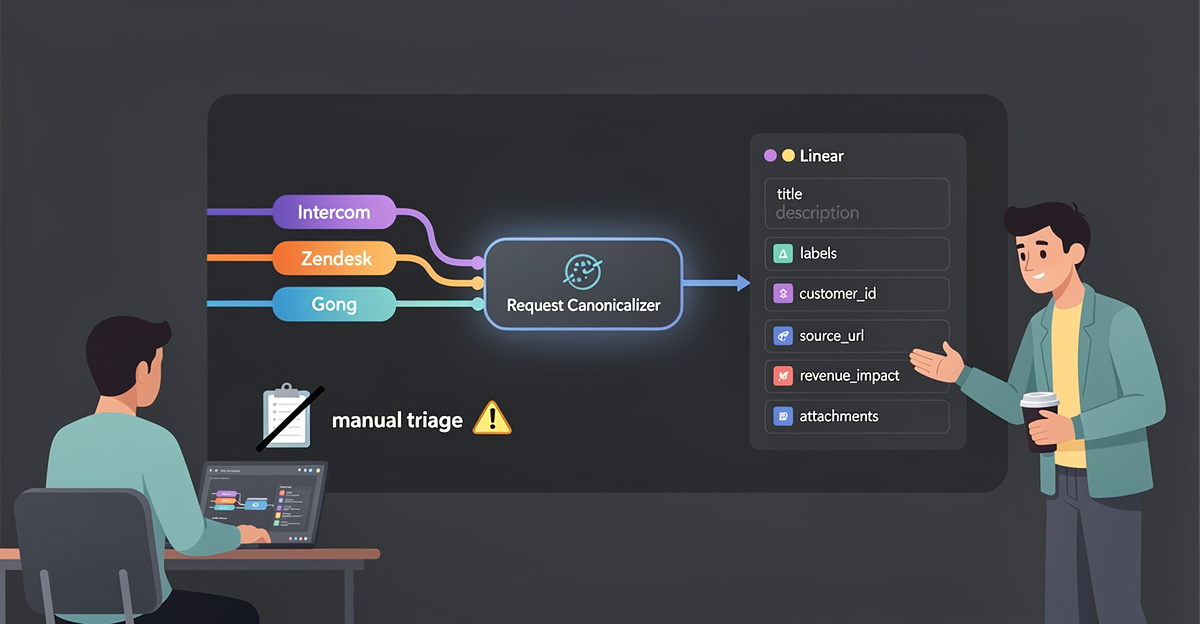
Manual triage is not “process.” It’s unpaid on-call for product teams. Every copy-pasted ticket drops context, mutates wording, and ships bad prioritization into Linear. The fix is not another bloated enterprise graveyard where feedback goes to die. The fix is a deterministic sync path that turns customer signals into Linear issues with stable IDs, dedupe rules, and audit logs.
Chapter 1 tightens intake: map Intercom, Zendesk, and Gong events into a single request shape that Linear can accept without humans rewriting it. Chapter 2 explains what MCP servers change: tool calling, scoped auth, and structured context that can create or update Linear issues safely. Chapter 3 gets tactical on latency and overhead: webhooks, rate limits, retries, and idempotency so you stop creating duplicates at 2 a.m. Chapter 4 looks at 2026 product ops: auto-linking revenue, summarizing calls, and keeping your roadmap honest without hiring a “triage team.”
Automated Request Processing That Syncs Cleanly to Linear: Stop Translating Customers Into Tickets
The bottleneck is not “too many requests.” It’s humans rewriting customer language into internal tickets, then losing context on the way into Linear.
Automated customer request processing is moving past basic ticket creation. The newer pattern is end-to-end resolution where the system reads the request, gathers context, and takes action across your tools. Instead of generating a Linear issue by default, an agentic system can check the customer’s account state, inspect the relevant operational system, and decide whether the right outcome is a fix, a refund, a workaround, or an engineering task. When it does create work for engineering, it can include what humans forget: error logs, related incidents, and the customer impact summary.
This matters for syncing customer requests to Linear without manual triage bottlenecks. If your automation only files tickets, Linear becomes a queue of half-understood work. If your automation resolves what it can and escalates what it must, Linear stays a system for true product and engineering work. The research also calls out supporting components that make this practical: omnichannel intake, routing by complexity or skills, sentiment-based prioritization, and pre-surfaced context that speeds agent resolution.
The business impact is why founders keep pushing this direction: reported outcomes include 80% reduction in helpdesk overload, call turnaround dropping from 45 minutes to 1.1 minutes, and 40% faster ticket resolution when the right context is attached.
How Feedvote solves this Feedvote captures feedback where it originates, then structures it so Linear doesn’t become a translation exercise. You get a clean path from customer language to actionable work, without losing the original context. Feedvote also supports two-way sync patterns so status updates don’t require manual follow-ups. If you want the workflow details, see the guide on a Linear feedback portal with 2-way sync.
Safe, Typed, Audited MCP Writes: Let Customer Requests Hit Linear Without Creating a Triage Incident
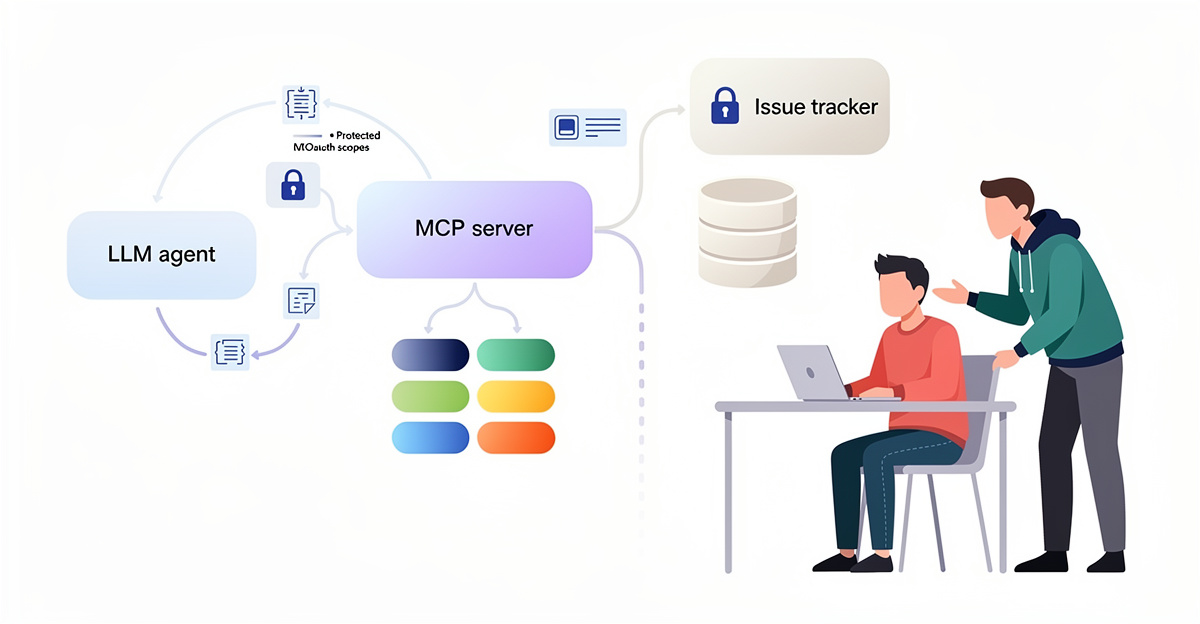
Manual triage fails the moment you let an agent write into Linear without guardrails. One bad mapping, and you get wrong projects, broken templates, and zero accountability.
MCP (Model Context Protocol) servers are built for this exact problem: they expose tools that let agents perform safe, typed, and audited linear writes into enterprise systems. “Linear” here means sequential, controlled updates, not “Linear the product,” but the same constraints apply when the destination is a Linear issue. Safety shows up as confirmations and scoped actions. Spec Workflow MCP supports checks, step skipping, and explicit confirmations before batch writes, which is what you want when a customer request fans out into multiple issue fields. Datadog’s MCP approach also avoids destructive writes by creating reviewed Jira tickets via an Atlassian integration, keeping humans in the loop when impact is uncertain.
Typed writes matter because customer inputs are messy. MCP servers expose typed schemas through tool discovery, so the agent has a contract for each action. Approval Studio’s MCP exposes REST/GraphQL-backed actions with typed tool definitions. Azure Logic Apps MCP expects HTTP Request/Response triggers with typed payloads, which is a clean boundary for turning “customer said X” into “issue.create with these fields.” Oracle’s MCP tooling emphasizes richer context management and schema inference over stateless REST, which helps when the agent needs to keep state across a multi-step create.
Auditing is the difference between automation and mystery. Azure Logic Apps integrates with Application Insights/Log Analytics for run history and diagnostics. Datadog MCP logs queries and automated ticket creation. That gives you traceability when you later ask, “Why did this request become that issue?”
How Feedvote solves this Feedvote treats “write to Linear” as a controlled operation, not a side effect. It keeps customer context attached, so the agent isn’t guessing fields from a single message. It also makes it easier to maintain a two-way relationship between the request and the Linear artifact, so audit and follow-up stay intact. If you want the workflow pattern, start with Feedvote’s guide on a Linear feedback portal with 2-way sync: https://blog.feedvote.app/linear-feedback-portal-2-way-sync/
Kill the Duplicate Storm: Webhooks, Dedupe, and Backpressure for Fast, Clean Linear Sync

If you pipe customer requests into Linear in real time, retries will bite you. Without controls, one outage turns into a duplicate storm and a week of manual cleanup.
Webhooks are the right ingestion shape because they push events instead of forcing polling. That cuts latency and removes the “check again later” loop. But webhook delivery is not a guarantee of exactly-once behavior. Providers retry on timeouts and 5xx responses, and clients sometimes retry too. So the real design problem is not “how do we receive events,” it’s “how do we receive events safely and turn them into Linear issues once.”
That means dedupe in the write path. Inline deduplication keeps data quality intact when volume spikes or when upstream repeats the same payload. For any non-idempotent operation—like creating a Linear issue—never retry without an idempotency key. If you do, you will create duplicates, charge twice, or corrupt state. Treat the key as a contract across your webhook handler, queue, and worker. If you can’t correlate events, you can’t prevent storms.
Then add backpressure or your system collapses under burst load. Backpressure is flow control: bounded concurrency, semaphores, connection pools, timeouts, and explicit state limits. When queues grow, you slow producers or shed load instead of burning memory and cascading failures. Combine the three: webhooks for low-latency ingestion, dedupe during validation, and backpressure in workers and queues. Use jittered retries and graceful shutdowns so in-flight work drains cleanly.
How Feedvote solves this Feedvote is built around syncing feedback into Linear without manual triage bottlenecks. It treats inbound signals as an event stream that must be safe under retries and spikes. The workflow assumes duplicates will happen and prevents them from turning into duplicate Linear issues. If you want the end-to-end model, start with this guide on two-way Linear feedback portal sync: https://blog.feedvote.app/linear-feedback-portal-2-way-sync/.
Requests That Arrive in Linear Pre-Prioritized: Revenue, Evidence, and Outcomes Without a Triage Queue

Your Linear intake breaks when every request lands as the same blank “feature ask.” Then a human has to translate messy customer context into priority, revenue impact, and next steps.
In 2026 PM practice, the goal is simple: a request should carry its own business meaning. Instead of shipping lists, teams frame work as outcomes tied to KPIs. That turns “build X” into “reduce trial-to-paid time from 14 days to 7 days.” When an item hits Linear with that framing, it’s already ranked against an outcome roadmap. It does not need a triage team to guess why it matters.
The second shift is evidence-first framing. Requests start with the user problem, business objective, constraints, and assumptions. Validation and measurement are part of the request, not an afterthought. AI fluency accelerates this by synthesizing customer inputs, drafting specs, generating hypotheses, and querying data in natural language. The request becomes a packaged decision unit: what we believe, what we saw, and what we’ll measure.
This also changes ownership. PMs act like business owners, accountable to metrics and tradeoffs. That means prioritization happens upstream, anchored to KPIs, not downstream in a backlog grooming meeting. The result is fewer “maybe later” tickets and more closed-loop work that is measurable.
How Feedvote solves this Feedvote structures incoming customer requests so they don’t arrive as raw text. It keeps the request tied to evidence and intent, then syncs it into Linear without forcing a human to rewrite it. That gives your team a consistent unit of work that maps to outcomes and measurement. The workflow stays fast because prioritization signals are captured at intake, not bolted on later.
If you’re building this workflow, start with a two-way Linear feedback portal sync so requests stay connected to decisions and updates: https://blog.feedvote.app/linear-feedback-portal-2-way-sync/
Final thoughts
Manual triage bottlenecks happen when intake is untyped, async, and owned by whoever is most patient. Syncing customer requests to Linear without that mess means three things: a canonical request shape, a safe automation layer that can write to Linear, and an ingestion pipeline that is built for duplicates and spikes.
Automated processing keeps source links, customer IDs, and evidence attached to the issue. MCP-style servers make the automation accountable with scoped auth, tool-level permissions, and audit logs. Webhooks plus queues keep latency low while protecting Linear from rate-limit thrash. The 2026 move is enrichment by default: revenue context, call summaries, and clustering arrive at creation time, so prioritization is based on data, not whoever yells loudest.
If your Linear triage is clean, engineers trust it. If engineers trust it, work ships faster. That is the whole game.
Start syncing customer feedback directly to Linear Triage with Feedvote—no manual work required.
Learn more: https://feedvote.app
About us
Feedvote is a customer feedback + public roadmap platform. It replaces Canny and Productboard for teams who want less bloat, lower cost, and faster workflows. It integrates deeply with Linear, but works as your source of truth for feedback. You collect requests, dedupe them, cluster them, and then sync the right artifacts into Linear Triage with links back to the original customer evidence.